A common approach for the virtual integration of several data sources, each of which maintains some autonomy, is regulation-compliant data processing. Early federated technologies came about as a result of mergers, acquisitions, and specialized corporate applications. However, the recent demand for decentralized data storage and computation in information marketplaces as well as for Geo-distributed data analytics has made federated data services an essential part of the data systems market. In addition, federated data processing is now governed by regulatory authorities because to growing privacy concerns raised by rules in different parts of the world.
This blog will cover the difficulties in developing federated data processing systems that are compatible with regulations as well as Databloom’s initiatives to make compliance a first-class citizen in our Blossom Data Platform.
What is Federated Data Processing?
In order to run analytics in a federated environment, distributed data processing capabilities are needed that can: (1) provide a unified query interface for analyzing distributed and decentralized data; (2) transparently translate a user-specified query into a so-called query execution plan; and (3) execute plan operators across compute sites. The query optimizer is a crucial part of the processing pipeline in this case. A query optimizer typically takes into account communication costs between compute nodes, distributed execution strategies (which involve distributing query operators like join or aggregation across compute nodes), and introduces a global property that specifies where, i.e., at which site, processing of each plan operator happens. For instance, to conduct a two-way join query over data sources in Asia, Europe, and North America, data from North America and Europe and then joining with the data in Asia.
Growing Data Regulations – A New Challenge
As is evident, federated inquiries imply the transfer of data (i.e., intermediate query results) between compute sites. The federate nature of data processing has recently been challenged by data transfer regulations (or policies) that restrict the movement of data across geographical (or institutional) borders as well as by any other data protection rules that may apply to the data being transferred between certain sites. This is true even though several performance aspects, such as bandwidth, latency, communication cost, and compute capabilities, have received significant attention.
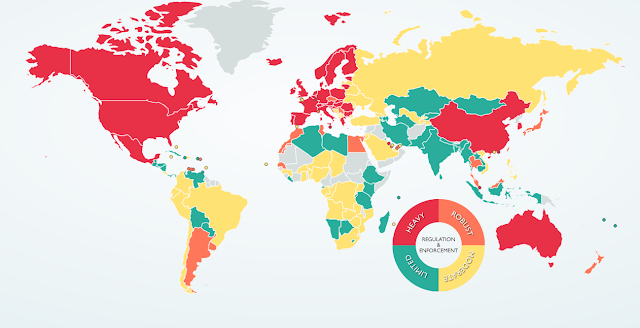
Only specific information fields (or combinations thereof), such as non-personal information or information unrelated to a person, are regulated by European directives, for instance. Similar laws may impose limitations on data transit in Asia. Billion-dollar fines have been imposed for failure to comply with such regulatory requirements. Therefore, when examining federated data, it is essential to take legal compliance into account.
Data Transfer Regulations through the GDPR lens
Currently, most nations throughout the world have different data protection laws that place limitations on how data is stored, processed, and transferred. The most notable of these are the California Consumer Privacy Act (CCPA) and the EU General Data Protection Regulation (GDPR).
Take GDPR as an illustration. Articles 44 to 50 of the GDPR specifically address the transmission of data across international boundaries. Among these, there are two articles and one recital in which it is stated that the federated data processing is profoundly impacted by the legal requirements for data transfer.
Article 45: Transfers on the basis of an adequacy decision.
The article dictates that transfer of data may take place without any specific authorization, e.g., when there is adequate data protection at the site where data is being transferred or when data is not subjected to regulations (i.e., when the data does not follow the definition of personal data as in Article 4(1)).
Article 46: Transfers subject to appropriate safeguards.
This article prescribes that (in the absence of applicability of Article 45) data transfer can take place under “appropriate safeguards”. Based on the European Data Protection Board (EDPB) recommendations that supplement transfer tools, pseudonymisation of data (as defined under Article 4(5)) is considered as an effective supplementary method.
Recital 108: Transfers under measures that compensate lack of data protection.
Data after adequate anonymization (i.e., when resulting data does not fall under Article 4(1) and as described in Recital 26) does not fall under the ambit of GDPR and therefore can be transferred.
Depending on the data and to where that data is being transferred, the above regulations can be classified into:
- No restrictions on transfer: Some data maybe allowed to be transferred unconditionally, and some to only certain locations.
- Conditional restrictions on transfer: For some data, only derived information (such as aggregates) or only after anonymization, can be transferred to (certain) locations.
- Complete ban on transfer: Some data, no matter whatsoever, must not be transferred outside.
Compliance-by-Design: The Challenges
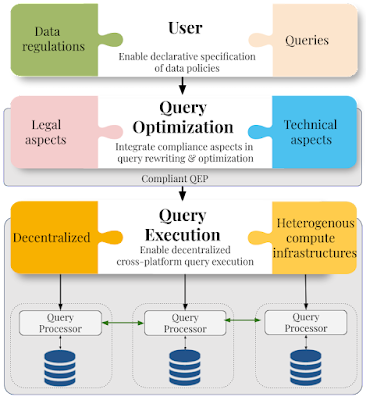
Rather than ad-hoc solutions to make data processing regulation-compliant, a more holistic approach that provides appropriate safeguards to data controllers (entities that control what data and how data should be processed) and data processors (entities that processes data on behalf of a controller) within a federated data processing system is required.
In the context of federated data processing, three aspects must to be revisited:
- First and foremost, data processing systems must offer declarative policy specification languages, which makes it easy and simple for controllers to specify data regulations. Policy specification languages should take into account the type of data, its processing, as well as the location of processing. Regulations may affect processing of an entire dataset, a subset of it, or even information that is derived from it. Policy specifications must also be considered keeping in mind the heterogeneity of data formats (e.g., graph, relational, or textual data).
- The second aspect of ensuring that compliance is at the core of federated data processing is integrating legal aspects in query rewriting and optimization. A system must be able to transparently translate user queries into compliant execution plans.
- Lastly, federated systems must offer capabilities to decentralize query execution, which may also be desired by the compliant plan. We need query executors that can efficiently orchestrate queries over different platforms across multiple clouds or data silos.
References
[2] Kaustubh Beedkar, David Brekardin, Jorge-Arnulfo Quiané-Ruiz, Volker Markl: Compliant Geo-distributed Data Processing in Action. Proc. VLDB Endow. 14(12): 2843-2846 (2021)
[3] Kaustubh Beedkar, Jorge-Arnulfo Quiané-Ruiz, Volker Markl: Navigating Compliance with Data Transfers in Federated Data Processing. IEEE Data Eng. Bull. 45(1): 50-61 (2022)
Tech.mt releases all liability on the quality or reliability of offerings / delivery of any products/services advertised or pitched from a sales point of view in any of the articles submitted.



